|
|
| Prof. Tao An and collaborators are in the finalists for the 2020 "Gordon Bell Prize" |
 |
Text Size: A A A |
|
[November 16, 2020] "Processing full-scale Square Kilometre Array workflow on the Summit supercomputer", with the participation of Professor Tao An and Mr. Baoqiang Lao of the Shanghai Astronomical Observatory (SHAO), Chinese Academy of Sciences (CAS), is in the finalist for the 2020 Gordon Bell Prize[1], the highest awards in the field of high performance computing (HPC). The final results of the 2020 Gordon Bell Prize will be announced at the International Conference on Supercomputing, to be held in the United States on 19 November (20 November Beijing Time). The Square Kilometre Array (SKA) is the largest radio telescope to be built, consisting of more than 2,000 dish antennas, millions of log-periodic antennas and hundreds of dense aperture arrays, which will open up a new era of the exploration of the Universe. The SKA will achieve extremely high sensitivity with its large collecting area, high spatial resolution with a maximum baseline of thousands of kilometers, fine temporal signals with nanosecond sampling, and generate data flow at rates of up to 10 peta bit per second that exceed the total capacity of the current global Internet. One of the key bottlenecks of the SKA is how to properly process the SKA big data, as it is tied to whether the SKA can achieve the expected scientific breakthrough. The construction of SKA will start in 2021, the first phase of the project (SKA1) is expected to be completed in 2029, and SKA's data processing system has entered the critical engineering validation and implementation stage. The SKA data processing is carried out in a real-time mode, thus requiring the workflow to have a high level of stability, scalability and energy consumption. The pre-processed data is transmitted via high-speed broadband internet to several regional data centers located in major member countries for in-depth analysis, and scientists primarily conduct scientific research based on the regional data centers. The team exceeded expectations by simulating and processing the complete data processing workflow of the SKA1 low-frequency telescope. That includes a real-time pipeline of observational data generation, acquisition, correlation, calibration, and imaging, using Summit, the world's fastest supercomputer at the time, developed by IBM and operated by Oak Ridge National Laboratory. The Summit’s computation power, up to 200 peta flops (Pflops for short), is comparable to that of the supercomputer of the SKA1 and is the best platform to validate the SKA data processing system. The paper describes in detail the breakthroughs made in the execution framework, parallelized input/output (I/O) and scaling-up execution of the SKA data processing system. The experiments are oriented to the key science project of SKA "Exploration of the Era of the Cosmic Re-ionization", using the sky model obtained by combining observational data and theoretical calculations, together with the design configuration of the SKA1 low-frequency telescope array (including 512 stations, each station has 256 antennas, so the total number of antennas is 131,072). The volume of the generated data reaches 2.6 petaByte (PB). This data mimic the observations at the frequency range 46-221MHz, requiring a total of 27,648 GPUs, using 99% of Summit's resources. 
Fig. 1: Epoch of Reionization simulation based on SKA1 low array configuration. Image Credit: ICRAR,ORNL,SHAO Radio astronomical interferometric data are stored in the MeasurementSet data format, a tabular-format data built on the CTDS system, with each table containing dozens of files. For SKA-scale data streams[2], data I/O becomes the most critical technical bottleneck. The initial CTDS did not support parallel processing, so the team developed two softwares “AdiosStMan” and “Adios2StMan” to enable parallelization of the data I/O, and also refactored CTDS to achieve massive parallel I/O. Many architectural optimizations were made as well to the radio astronomy software core library to improve the efficiency of AdiosStMan. During the experiments, the data write rate reached a maximum of 925GB/s, which is 1.5 times higher than the design requirement of SKA1, indicating that there is a solution for handling data-intensive scientific computing problems like SKA involving large-scale I/O. The team developed a data flow execution framework named as DALiuGE specifically for SKA, which has obvious advantages in scalability and resilience[3]. The innovative design makes DALiuGE not only capable of satisfying the SKA data processing tasks, but also potentially valuable for other large scientific computing applications. In summary, this work successfully simulates an "end-to-end" SKA workflow, which simulates the pipeline processing of a typical SKA science experiment and exports image datasets. This is the largest data flow in astronomy to date, demonstrating the ability of astronomers to handle future scientific data processing tasks for the SKA and strengthening the confidence of the SKA community in handling the big data challenge. The key technological breakthroughs achieved in this work have strong potential for application and transformation in other large-scale scientific computing areas as well. 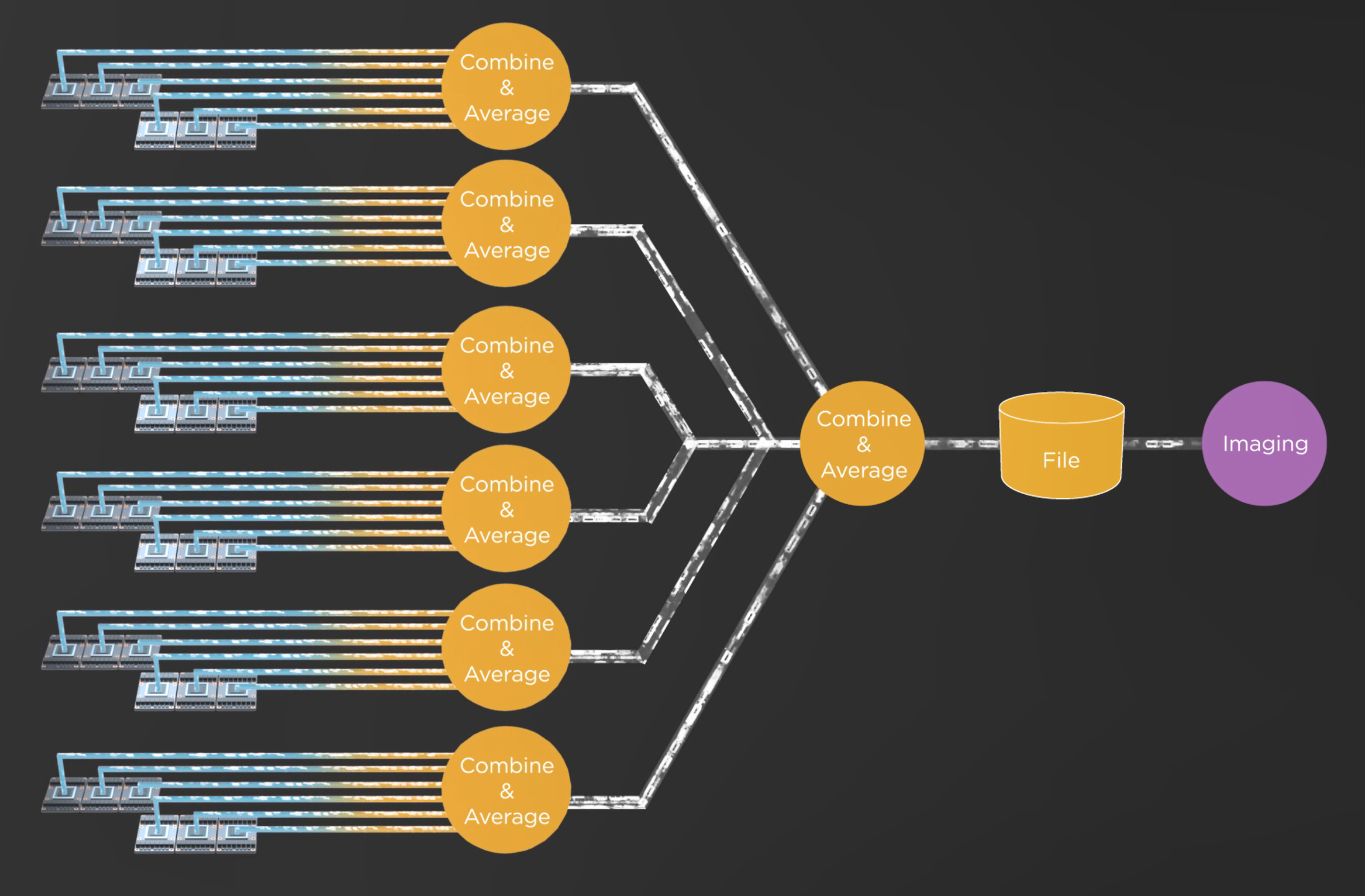 Fig.2: Illustration of the simulated SKA-Summit workflow. Image Credit: ICRAR,ORNL,SHAO 
Fig. 3: Illustration of the data cube generated by the experiment. Image Credit: ICRAR,ORNL,SHAO Other members of the team are from the University of Western Australia in Australia, Oak Ridge National Laboratory in the United States, and the University of Oxford in the United Kingdom. References: 1. "Processing Full-Scale Square Kilometre Array Data on the Summit Supercomputer," in 2020 SC20: International Conference for High Performance Computing, Networking, Storage and Analysis (SC), Atlanta, GA, US, 2020 pp. 11-22. doi: 10.1109/SC41405.2020.00006 2. “Processing Full-Scale Square Kilometre Array Data on the Summit Supercomputer” ACM Gordon Bell Finalist Awards Presentation, https://sc20.supercomputing.org/presentation/?id=gb102&sess=sess303 3. “SKA shakes hands with Summit,” Science Bulletin, Volume 65, Issue 5, 2020, Pages 337-339, https://doi.org/10.1016/j.scib.2019.12.016. [1] The Gordon Bell Prize is the highest international academic award in the field of high performance computing (HPC), known as the "Nobel Prize in Supercomputing", and is awarded annually for outstanding achievements in HPC. The purpose of the prize is to track the progress of parallel computing over time, with a particular emphasis on rewarding innovations in the application of HPC to science, engineering, and large-scale data analysis. [2] A typical SKA observation can generate millions or even billions of files, and such a tremendous amount of (small) files places an extreme strain on shared file systems, metadata management systems, data archiving systems, and so on. I/O parallelization is a critical technique bottleneck in data-intensive scientific computing like SKA. [3] DALiuGE adopts the concept of data-driven (or data-initiated) compute, which not only greatly improves scalability and flexibility, but also improves operational efficiency and has good fault tolerance. The system is highly resilient and adaptable, in the event of a few node errors or packet loss, the entire task process can continue to process the vast majority of the remaining data without serious impact on the overall process. DALiuGE projects the workflow to a directed acyclic graph, which can be efficiently scheduled, and its intelligent resource scheduling mechanism can significantly reduce the overall workflow energy consumption, which has practical implications in mega scientific computing. DALiuGE is able to manage up to tens of millions of tasks simultaneously, can execute data streams of up to Tb/s. DALiuGE is highly resilient to node errors, and experiments have shown that GPU nodes execute with an efficiency of up to 87%. |
|